 Hadoop gets plenty of attention from investors and the IT press, but it’s very possible we haven’t seen anything yet. All the action of the last year has just been setting the stage for what should be a big year full of new companies, new users and new techniques for analyzing big data. That’s not to say there isn’t room for alternative platforms, but with even Microsoft abandoning its competitive effort and pinning its big data hopes on Hadoop, it’s difficult to see the project’s growth slowing down.
Hadoop gets plenty of attention from investors and the IT press, but it’s very possible we haven’t seen anything yet. All the action of the last year has just been setting the stage for what should be a big year full of new companies, new users and new techniques for analyzing big data. That’s not to say there isn’t room for alternative platforms, but with even Microsoft abandoning its competitive effort and pinning its big data hopes on Hadoop, it’s difficult to see the project’s growth slowing down.
Here are six big things Hadoop has going for it as 2012 approaches.
1. Investors love it
Cloudera has raised $ 76 million since 2009. Newcomers MapR and Hortonworks have raised $ 29 million and $ 50 million (according to multiple sources), respectively. And that’s just at the distribution layer, which is the foundation of any Hadoop deployment. Up the stack, Datameer, Karmasphere and Hadapt have each raised around $ 10 million, and then are newer funded companies such as Zettaset, Odiago and Platfora. Accel Partners has started a $ 100 million big data fund to feed applications utilizing Hadoop and other core big data technologies. If anything, funding around Hadoop should increase in 2012, or at least cover a lot more startups.
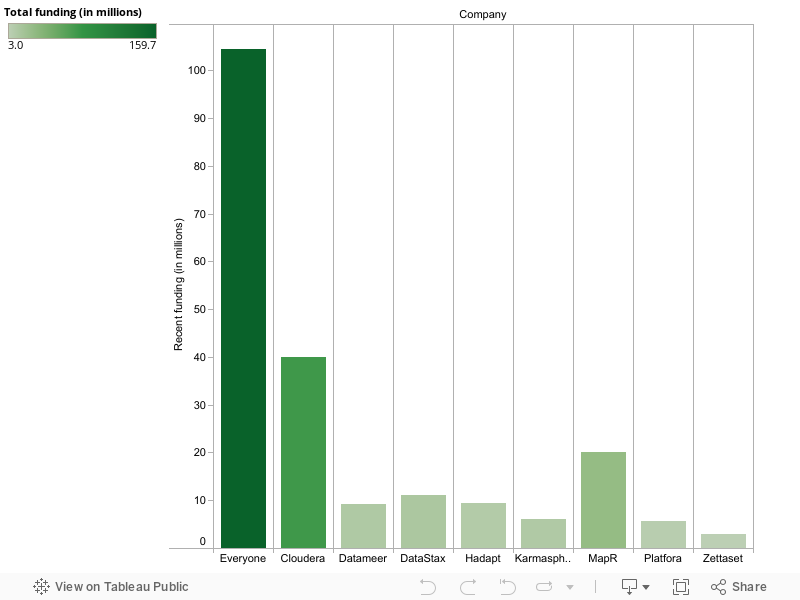
2. Competition breeds success
Whatever reasons companies had to not use Hadoop should be fading fast, especially when it comes to operational concerns such as performance and cluster management. This is because MapR, Cloudera and Hortonworks are in a heated competition to win customers’ business. Whereas the former two utilize open source Apache Hadoop code for their distributions, MapR is pushing them on the performance front with its semi-proprietary version of Hadoop. This means an increased pace of innovation within Apache, and a major focus on management tools and support to make Hadoop easier to deploy and monitor. These three companies have lots of money, and it’s all going toward honing their offerings, which makes customers the real winners.
3. What learning curve?
Aside from the improved management and support capabilities at the distribution layer, those aforementioned up-the-stack companies are already starting to make Hadoop easier to use. Already, Karmasphere and Concurrent are helping customers write Hadoop workflows and applications, while Datameer and IBM are among the companies trying to make Hadoop usable by business users rather than just data scientists. As more Hadoop startups begin emerging from stealth mode, or at least releasing products, we should see even more innovative approaches to making analytics child’s play, so to speak.
4. Users are talking
 It might not sound like a big deal, but the shared experiences of early Hadoop adopters could go a long way toward spreading Hadoop’s utility across the corporate landscape. It’s often said that knowing how to manage Hadoop clusters and write Hadoop applications is one thing, but knowing what questions to ask is something else altogether. At conferences such as Hadoop World, and on blogs across the web, companies including Walt Disney, Orbitz, LinkedIn, Etsy and others are telling their stories about they’ve been able to discover since they began analyzing their data with Hadoop. With all these use cases abound, future adopters should have an easier time knowing where to get started and what types of insights they might want to go after.
It might not sound like a big deal, but the shared experiences of early Hadoop adopters could go a long way toward spreading Hadoop’s utility across the corporate landscape. It’s often said that knowing how to manage Hadoop clusters and write Hadoop applications is one thing, but knowing what questions to ask is something else altogether. At conferences such as Hadoop World, and on blogs across the web, companies including Walt Disney, Orbitz, LinkedIn, Etsy and others are telling their stories about they’ve been able to discover since they began analyzing their data with Hadoop. With all these use cases abound, future adopters should have an easier time knowing where to get started and what types of insights they might want to go after.
5. It’s becoming less noteworthy
This point is critical, actually, to the long-term success of any core technology: at some point, it has to become so ubiquitous that using it’s no longer noteworthy. Think about relational databases in legacy applications — everyone knows Oracle, MySQL or SQL Server are lurking beneath the covers, but no one really cares anymore. We’re hardly there yet with Hadoop, but we’re getting there. Now, when you come across applications that involve capturing and processing lots of unstructured data, there’s a good chance they’re using Hadoop to do it. I’ve come across a couple of companies, however, that don’t bring up Hadoop unless they’re prodded because they’re not interested in talking about how their applications work, just the end result of better security, targeted ads or whatever it is they’re doing.
6. It’s not just Hadoop
 If Hadoop were just Hadoop — that is, Apache MapReduce and the Hadoop Distributed File System — it still would be popular. But the reality is that it’s a collection of Apache projects that include everything from the SQL-like Hive query language to the NoSQL HBase database to machine-learning library Mahout. HBase, in particular, has proven particularly popular on its own, including at Facebook. Cloudera, Hortonworks and MapR all incorporate the gamut of Hadoop projects within their distributions, and Cloudera recently formed the Bigtop project within Apache, which is a central location for integrating all Hadoop-related projects within the foundation. The more use cases Hadoop as a whole addresses, the better it looks.
If Hadoop were just Hadoop — that is, Apache MapReduce and the Hadoop Distributed File System — it still would be popular. But the reality is that it’s a collection of Apache projects that include everything from the SQL-like Hive query language to the NoSQL HBase database to machine-learning library Mahout. HBase, in particular, has proven particularly popular on its own, including at Facebook. Cloudera, Hortonworks and MapR all incorporate the gamut of Hadoop projects within their distributions, and Cloudera recently formed the Bigtop project within Apache, which is a central location for integrating all Hadoop-related projects within the foundation. The more use cases Hadoop as a whole addresses, the better it looks.
Disclosure: Concurrent is backed by True Ventures, a venture capital firm that is an investor in the parent company of this blog, Giga Omni Media. Om Malik, the founder of Giga Omni Media, is also a venture partner at True.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.
- Defining Hadoop: the Players, Technologies and Challenges of 2011
- Infrastructure Q2: Big data and PaaS gain more momentum
- Infrastructure Q1: IaaS Comes Down to Earth; Big Data Takes Flight
![]()