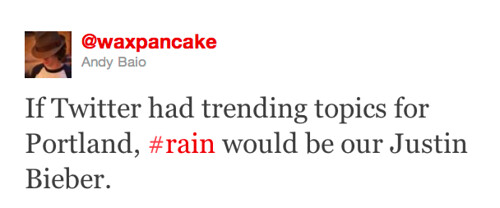
It was a year ago when Andy Baio posted this tweet, and in his (far less than) 140 characters perfectly captured the key elements in this blog post: trending topics, geographies, and exogenous/endogenous events.
Indeed, as Danah Boyd also pointed out on her blog,
There are two types of trending topics on Twitter: endogenous and exogenous. Endogenous TTs happen when a topic has a viral spread. Once it becomes a TT, everyone jumps onto it to spread it even further. So when we see a hashtag like #intenyears we know it didn’t happen naturally [snip]. Exogenous TTs happen when everyone is talking about the same thing simultaneously, not really responding to each other or to the trending topic per say but responding to a cultural moment. This often happens when there are major new events or TV shows that are broadcasting something of great interest.
There is some value judgment implicit in Danah’s post, which I still cannot pinpoint quite clearly; but it does seem that exogenous trends are of some higher value, perhaps because they reflect on events that occur in the physical world, not just the virtual one (granted, virtual events can eventually spread to the real world and affect it — ask Anthony Weiner — but it is not clear how often that happens).
My co-authors and I recently published a paper (pdf) that asked two related questions: What types of trending topics can be captured in Twitter data (using standard techniques)? What are the important dimensions according to which these trends can be characterized, and what are the key distinguishing features of trends that can assist in automatically categorizing and differentiating the different trending topics?
 To keep this post short, I would just mention that we did some qualitative coding and affinity analysis of a sample of trends from one geographic location (New York). This is with a computer science PhD student — Hila Becker — in her first dwelling into qualitative methods (yes, I am pretty proud of that, and her; Luis Gravano is another co-author on this NSF-funded work). The emerging categories we identified were split into “endogenous” and “exogenous” types, and included categories like breaking news events, broadcast media events (like the type Danah alludes to), planned events (like the pep rally mentions in Danah’s post) and so forth.
To keep this post short, I would just mention that we did some qualitative coding and affinity analysis of a sample of trends from one geographic location (New York). This is with a computer science PhD student — Hila Becker — in her first dwelling into qualitative methods (yes, I am pretty proud of that, and her; Luis Gravano is another co-author on this NSF-funded work). The emerging categories we identified were split into “endogenous” and “exogenous” types, and included categories like breaking news events, broadcast media events (like the type Danah alludes to), planned events (like the pep rally mentions in Danah’s post) and so forth.
We quickly transitioned to more traditional computer science tools, and took a sample of trends and all their associated data: tweets, networks of users and a bunch of derived variables (or “features”). The features were chosen with the hypothesis that they can help us automatically differentiate between different types of trends. We grouped these computed features into five categories:
- Content features (based on the content of messages for the trend, e.g., proportion of posts with URLs)
- Interaction features (the characteristics of conversation/social interaction in the trend’s content)
- Time features (how quickly the trend develops and dies)
- Participation features (how spread out versus centralized the trend is — are there a few key users posting content or not)
- Social network features (how dense is the network between users posting about that trend)
The social network features, for example, can perhaps help differentiate exogenous trends (where many people at once react to the same “event”) and endogenous trends (that may spread through connected people in the Twitter network). And indeed, as we show in the paper, that set of features did turn out to be different, in general, between endogenous and exogenous trends.
I leave you with the full paper to get more details about differences between trend types (clue: Table 5). However, this finding begs the question: can we use these features to automatically classify trends into exogenous or endogenous ones?
Well yes we can, at least to some degree. We show this result in our most recent paper, “Beyond Trending Topics: Real-World Event Identification on Twitter” (pdf, to be presented in Barcelona next week at the ICWSM conference). While we use a slightly different method to compute and detect “message clusters” (such as tweets that correspond to the same topic), we show that we can pretty robustly classify these clusters into those that reflect some real-world occurrence, and those that do not. Future work: show that this works with the full stream of Twitter data, and how early we can do it after the new trending topic was detected. In the meantime, in our second ICWSM paper, we show that we can also select top representative tweets for each cluster.
So, if we were in Portland with @waxpancake, our system could perhaps show that #rain is *not* a “Justin Beiber” because unlike most tweets about the young pop star, rain tweets and trending topics will correspond to a real-world occurrence (note to Bieber fans: I am not saying he is not real, but I guess this depends how you define “real”).
There are many other interesting social media papers at ICWSM, so be sure to check them out.
Mor Naaman is a professor at the Rutgers School of Communication and Information where he directs the Social Media Information Lab. He is a former Yahoo! Researcher, Stanford PhD student, and professional basketball player.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.
- Millennials in the enterprise, part 1: strategies for supporting the new digital workforce
- Infrastructure Q2: Big data and PaaS gain more momentum
- Players and Strategies for Real-Time In-Stream Advertising
![]()